Att förstå spatiala nätverk
Spatiala nätverk är ett enkelt men kraftfullt sätt att beskriva hur objekt är ordnade i rummet när vi inte från början har någon karta eller några koordinater.
I stället för att registrera var objekten finns, registrerar vi bara vilka som är kopplade till eller ligger nära varandra. Dessa kopplingar kan representera trådlös kommunikation mellan sensorer,
tågrutter mellan städer eller fysiska interaktioner mellan molekyler.
I ett sådant nätverk kallas objekten noder och kopplingarna mellan dem kallas kanter.
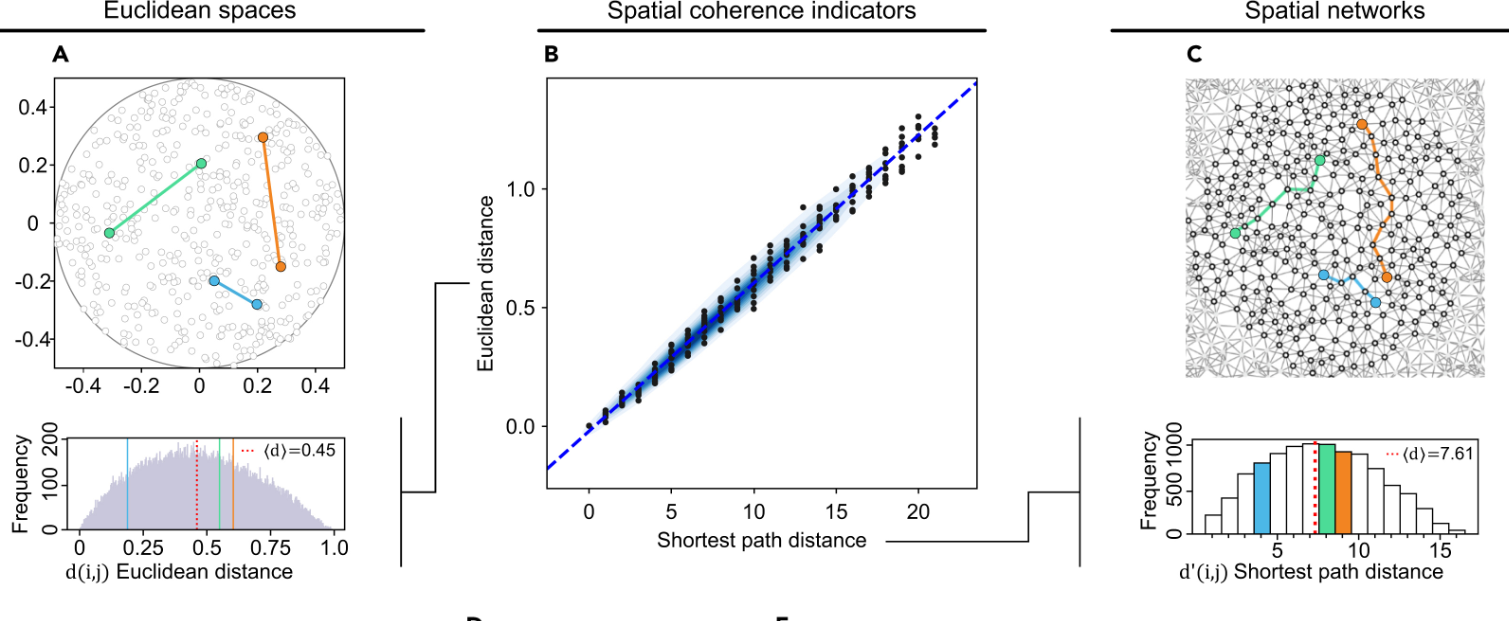
När kanter tenderar att länka samman närliggande objekt snarare än avlägsna objekt innehåller nätverket i tysthet information om rumslig struktur.
En central fråga i vår forskning är hur mycket av denna dolda spatiala information som kan återvinnas enbart från nätverket,
och vilka egenskaper som gör ett nätverk verkligt informativt om geometri snarare än bara om konnektivitet.
← Klicka!
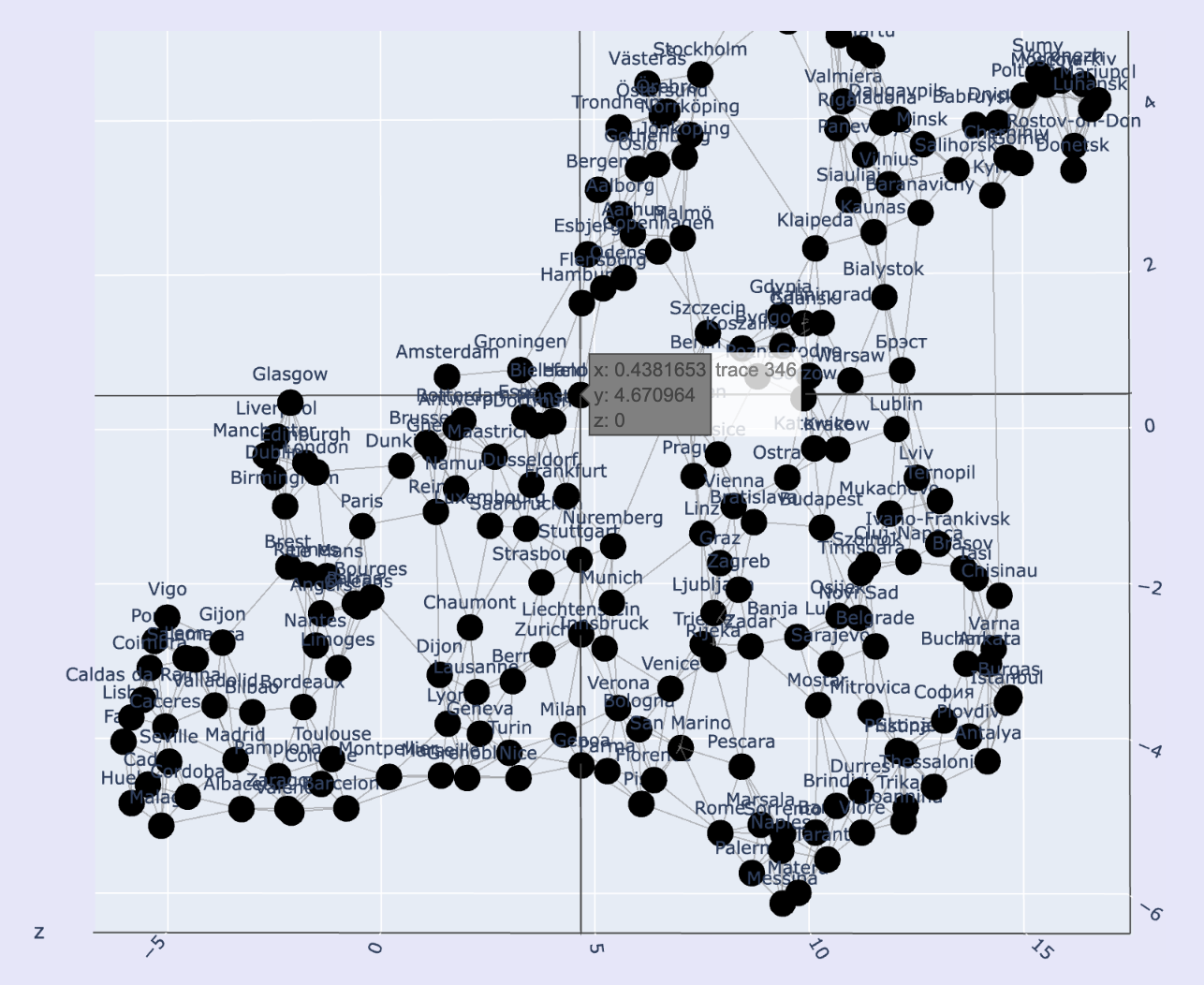
I den interaktiva panelen här representerar varje punkt (nod) en molekyl och varje linje (kant) en registrerad interaktion mellan närliggande molekyler.
Om du zoomar in i molnet av noder och kanter ser du att kanterna ofta kopplar samman spatiala grannar.
Det betyder att nätverkets struktur är korrelerad med fysisk närhet. Även när denna korrelation inte är perfekt
kan den ändå användas för att sluta sig till spatial organisation direkt från nätverket.
Klicka! →
En lång lista över regionala transportförbindelser i Europa, till exempel Stockholm till Köpenhamn eller Paris till Lyon, utgör ett spatialt nätverk. Ett nätverk är "spatialt" om kopplingarna är relaterade till avståndet mellan objekten.
En sådan lista över regionala förbindelser ger oss alltså information om var städerna ligger i förhållande till varandra i rummet.
Genom att optimera hur väl olika begränsningar uppfylls, det vill säga maximera närheten mellan sammanlänkade noder, kan vi återvinna den spatiala informationen och skapa en approximation.
Titta gärna på den interaktiva figuren här. Vi kan se några saker direkt: först och främst har de globala positionerna inte bevarats.
Men om du speglar och roterar bilden bör du kunna känna igen en mer bekant karta över Europa.
Kom ihåg att ingen koordinatinformation alls användes i denna rekonstruktion.
Att förstå spatiala nätverk berör ett grundproblem som delas av biologi, fysik och datavetenskap: hur tillförlitlig geometrisk information kan uppstå enbart ur lokala interaktioner.
Många naturliga och konstruerade system ger inte direkt tillgång till koordinater, utan kodar i stället rummet implicit genom mönster av konnektivitet, närhet eller interaktion.
Vårt arbete fokuserar på att identifiera de principer som gör sådana nätverk rekonstruerbara, och på att fråga när och varför ett nätverk faktiskt speglar ett underliggande fysiskt eller
geometriskt rum snarare än bara en abstrakt graf. Centralt i detta är begreppet spatial coherence, som fångar om nätverksavstånd beter sig på ett sätt som är förenligt med
geometriska begränsningar som dimensionalitet, skalning och geodetisk struktur.
Genom att studera hur kortaste väg-avstånd, spektrala egenskaper och skalningslagar relaterar till det fysiska rummet försöker vi skilja nätverk som bevarar spatial mening
från nätverk som förvrängts av brus, genvägar eller saknad information.
Utöver själva rekonstruktionen väcker spatiala nätverk bredare frågor om robusthet, brustolerans och design. Verkliga nätverk innehåller ofta falska eller långväga kopplingar, ojämn sampling eller heterogen densitet, vilket alla kan sudda ut den spatiala strukturen. I stället för att se dessa effekter som enbart negativa studerar vi hur nätverksegenskaper som konnektivitet och redundans påverkar balansen mellan signal och förvrängning. Det perspektivet gör det möjligt för oss att utveckla kvalitetskontrollmått utan ground truth och principiella sätt att bedöma om en datamängd sannolikt kan stödja tillförlitlig spatial inferens. Mer generellt syftar vår forskning till att etablera en teori för spatiala nätverk som fungerar över flera modaliteter, från molekylära och cellulära system till sensornätverk och abstrakta embeddingar, och som ger verktyg för att resonera om rum när rummet självt inte observeras direkt.
Relaterade publikationer och länkar:
- Bonet DF, Blumenthal JI, Lang S, Dahlberg SK, Hoffecker IT. Spatial coherence in DNA barcode networks. Patterns. 2025 Dec 12;6(12).
cell.com
- Bonet DF, Hoffecker IT. Image recovery from unknown network mechanisms for DNA sequencing-based microscopy. Nanoscale. 2023;15(18):8153-7.
pubs.rsc.org
- Hoffecker IT, Yang Y, Bernardinelli G, Orponen P, Högberg B. A computational framework for DNA sequencing microscopy. Proceedings of the National Academy of Sciences. 2019 Sep 24;116(39):19282-7.
pnas.org
Nätverksbaserad 2D spatial transkriptomik
Spatial transkriptomik är en samling teknologier som gör det möjligt att mäta vilka gener som är aktiva i en
vävnad samtidigt som deras fysiska positioner bevaras. Detta är viktigt eftersom biologisk funktion inte enbart bestäms av genaktivitet,
utan också av hur olika celltyper är ordnade, interagerar och bildar strukturer som lager, gradienter
och mikromiljöer. Genom att lägga till ett spatialt sammanhang till mätningar av genuttryck kan spatial transkriptomik hjälpa forskare
att studera vävnadsorganisation vid utveckling, cancer och sjukdom, och att koppla molekylära program till anatomi på ett direkt
och kvantitativt sätt.
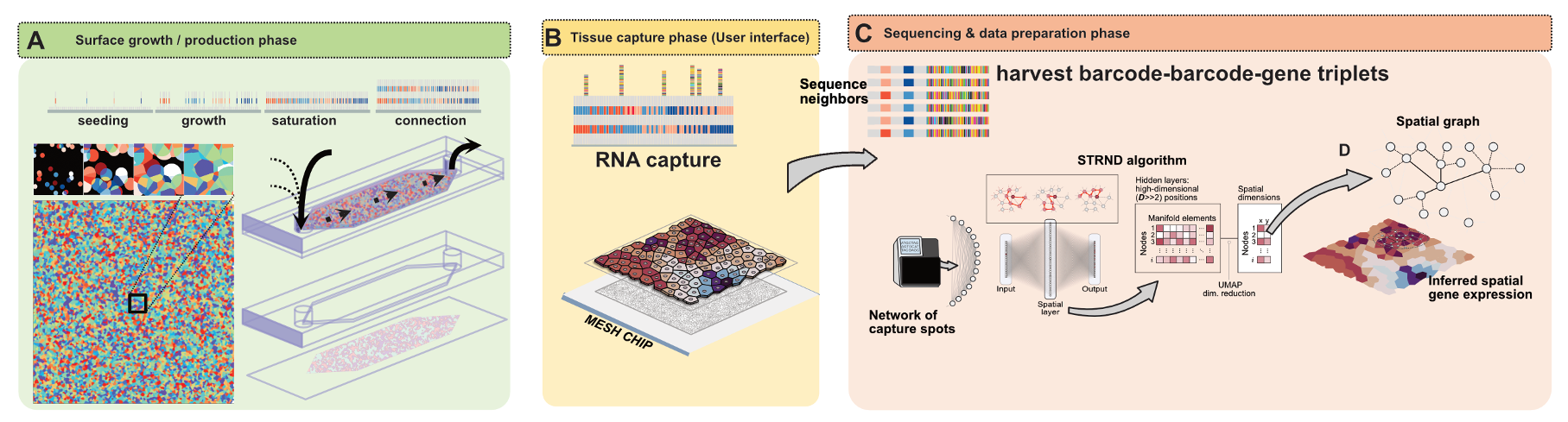
Nätverksbaserad 2D spatial transkriptomik är en framväxande klass av metoder som kodar spatial information implicit genom molekylär
närhet snarare än explicit genom fördefinierade koordinater.
I stället för att förlita sig på tryckta rutnät, litografi eller optisk avkodning för att tilldela positioner
genererar dessa metoder täta samlingar av molekylära infångningspunkter vars lokala grannskapsrelationer registreras i sekvenseringsdata. Genom att läsa ut vilka molekylära barcodes som tenderar att uppträda tillsammans på grund av fysisk närhet på en yta får man en graf vars struktur speglar den underliggande vävnadsgeometrin.
Spatiala positioner härleds sedan beräkningsmässigt genom att rekonstruera en tvådimensionell layout som är så förenlig som möjligt med den observerade nätverkskopplingen,
på ungefär samma sätt som man kan rekonstruera en karta från en lista över lokala förbindelser.
Detta nätverksperspektiv flyttar spatial transkriptomik från ett tillverkningsproblem till ett inferensproblem.
Spatial upplösning och kartlagd area bestäms inte längre av tillverkningsprecisionen, utan uppstår i stället ur tätheten och kvaliteten hos de lokala kopplingarna
i nätverket samt de rekonstruktionsalgoritmer som används nedströms. Som följd erbjuder dessa metoder en väg mot storskalig och högkapacitetsbaserad spatial
profilering med hjälp av enkla, självorganiserade infångningsytor kombinerade med standardiserad sekvensering. Mer generellt knyter nätverksbaserad spatial transkriptomik samman molekylär
biologi med grafteori och statistisk inferens, och öppnar nya möjligheter att studera vävnadsorganisation, gradienter och multicellulär struktur i stor skala samtidigt som
kostnad och teknisk komplexitet minskar.
Relaterade publikationer och länkar:
- Benson E, Hoffecker IT. Capture surface of metapolonies. Swedish Patent SE547614C2. Application filed January 15, 2024. Published October 28, 2025.
patents.google.com
- Hoffecker IT, Yang Y, Bernardinelli G, Orponen P, Högberg B. A computational framework for DNA sequencing microscopy. Proceedings of the National Academy of Sciences. 2019 Sep 24;116(39):19282-7.
pnas.org
- Two researchers in Sweden to receive an ERC Proof of Concept Grant
www.vr.se
- Spatial transcriptomics chips with sequencing-based microscopy
cordis.europa.eu
- Dahlberg SK, Bonet DF, Franzén L, Ståhl PL, Hoffecker IT. Hidden network preserved in Slide-tags data allows reference-free spatial reconstruction. Nature Communications. 2025 Oct 31;16(1):9652.
nature.com
3D-molekylär rekonstruktion med sekvenseringsbaserad mikroskopi

Tredimensionell molekylär avbildning syftar till att avslöja hur celler, gener och biomolekyler är organiserade och interagerar inne i
intakta vävnader och organ. Detta spatiala sammanhang är avgörande för att förstå utveckling, sjukdomsförlopp och hur
komplexa biologiska funktioner uppstår ur lokala interaktioner. Idag bygger den mesta högupplösta 3D-avbildningen på optisk mikroskopi,
som möter grundläggande utmaningar när prover blir tjockare och mer komplexa. Ljusspridning, absorption, begränsat penetrationsdjup
och behovet av avancerade klarnings- eller snittningsprotokoll begränsar upplösning, genomströmning och skalbarhet. Därför förblir många biologiska
system svåra eller omöjliga att avbilda heltäckande i tre dimensioner med enbart optik.
Vår forskning utforskar en alternativ väg till 3D-molekylär avbildning som inte bygger på linser eller ljus. I stället för att mäta spatial
position direkt kodar vi spatial närhet i nätverk av interagerande molekylära barcodes. När molekyler ligger nära varandra i
det fysiska rummet är det mer sannolikt att de interagerar, koassocierar eller fångas upp tillsammans. Genom att läsa ut dessa interaktioner med hjälp av högkapacitets-
sekvensering av DNA får vi stora molekylära nätverk vars konnektivitet speglar den underliggande tredimensionella strukturen i
provet. I detta ramverk lagras spatial information implicit i vem som är kopplad till vem, snarare än explicit i pixlar eller voxlar.
Från dessa molekylära nätverk rekonstruerar vi den tredimensionella spatiala organisationen beräkningsmässigt. Med grafbaserad inferens
återvinner vi layouter som är mest förenliga med de observerade konnektivitetsmönstren, och bygger därmed i praktiken upp en 3D-karta från lokala grannskapsrelationer
enbart. Denna nätverksbaserade och optikfria metod flyttar 3D-mikroskopi från ett hårdvarubegränsat avbildningsproblem till ett datadrivet
inferensproblem. Den öppnar en väg mot skalbar molekylär avbildning på vävnadsnivå och potentiellt på hela organ, med sekvensering som primär
avläsningsmetod, där upplösning och volym bestäms av nätverkstäthet och molekylär design snarare än av optiska begränsningar.
Relaterade publikationer och länkar:
- Bonet DF, Blumenthal JI, Lang S, Dahlberg SK, Hoffecker IT. Spatial coherence in DNA barcode networks. Patterns. 2025 Dec 12;6(12).
cell.com
- Bonet DF, Hoffecker IT. Image recovery from unknown network mechanisms for DNA sequencing-based microscopy. Nanoscale. 2023;15(18):8153-7.
pubs.rsc.org
- Instrument-free 3D molecular imaging with the VOLumetric UMI-Network EXplorer
cordis.europa.eu
- VOLUMINEX Project Webpage
voluminex-project.eu/
- SciLifeLab-led consortium receives Pathfinder grant to enable sequencing-based microscopy in 3D
scilifelab.se
- KTH med och delar på 11,7 miljoner euro till deep tech
kth.se
- The Future of 3-D Molecular Imaging in Life Sciences with Ian Hoffecker
singletechnologies.com
Teknologi och evolutionär beräkning
Teknologi kan förstås som en form av beräkning som utförs i den fysiska världen. Varje teknologisk process kodar regler, begränsningar och minne och utvecklas genom sekvenser av villkorade handlingar, ungefär som ett program som körs. Med tiden förändras tekniska lösningar genom processer som nära påminner om biologisk evolution: varianter genereras, testas i samspel med sin omgivning och bevaras selektivt. Innovation är i detta perspektiv inte ett enskilt ögonblick av uppfinning, utan en evolutionär process formad av variation, selektion och arv. Detta synsätt gör det möjligt att studera teknologier, från molekylära system till storskaliga materiella praktiker, som evolverande populationer styrda av allmänna principer för informationsbearbetning.
Vår forskning utforskar dessa principer på en grundläggande nivå genom att utveckla formella modeller av teknologi som en generativ process. Vi studerar hur strukturerad design uppstår ur sekvenser av beroende operationer, hur tekniker och delkomponenter återanvänds i olika konstruktioner och hur materiella resultat bara bevarar en del av informationen om de processer som skapade dem. Genom att betrakta teknologisk produktion som en stokastisk och hierarkisk process med dold intern organisation försöker vi förstå både hur komplexa teknologiska system uppstår och vad som kan utläsas om dem från ofullständiga fysiska spår.
Dessa idéer informerar också vårt intresse för evolutionär beräkning som designstrategi inom molekylär programmering. Genom utvalda samarbeten arbetar vi med system där variation och selektion används för att utforska funktionella designrum, till exempel DNA-baserade molekylära bindare som formas genom iterativ selektion. I detta sammanhang fungerar evolutionära processer både som konceptuell modell och som praktiskt verktyg, och visar hur beräkning, anpassning och fysisk implementering kan sammanfalla. Detta forskningstema placerar evolutionär beräkning som ett förenande perspektiv för att förstå teknologi över flera skalor, utan att göra något enskilt tillämpningsområde till huvudfokus.
Relaterade publikationer och länkar:
- Benson E, Hoffecker IT. Random DNA structures. International Patent Application WO2024260866. Application filed June 14, 2024. Published December 26, 2024.
patentscope.wipo.int
- Hoffecker JF, Hoffecker IT. Technological complexity and the global dispersal of modern humans. Evolutionary Anthropology: Issues, News, and Reviews. 2017 Nov;26(6):285-99.
onlinelibrary.wiley.com
- Hoffecker JF, Hoffecker IT. Measuring the computational complexity of artifact design in Paleolithic archaeology.
researchgate.net
- Hoffecker JF, Hoffecker IT. The structural and functional complexity of hunter-gatherer technology. Journal of Archaeological Method and Theory. 2018 Mar;25(1):202-25.
link.springer.com
Spatialt programmerad immunkemi
På den mest grundläggande nivån ställer denna forskning en enkel fråga:
hur känner immunförsvaret av och reagerar på molekylers spatiala
arrangemang, inte bara deras kemiska identitet?
I levande system kodas många biologiska signaler i mönster.
Virus, bakterier och syntetiska vacciner presenterar ofta antigener
i starkt organiserade arrayer på nanoskala, och immunreceptorer
binder inte dessa mönster passivt. I stället utforskar de dem fysiskt.
Genom att skapa noggrant kontrollerade molekylära landskap
kan vi studera hur antikroppar rör sig, binder och samarbetar över rummet,
och därmed avslöja regler som annars är dolda i komplexa biologiska miljöer.
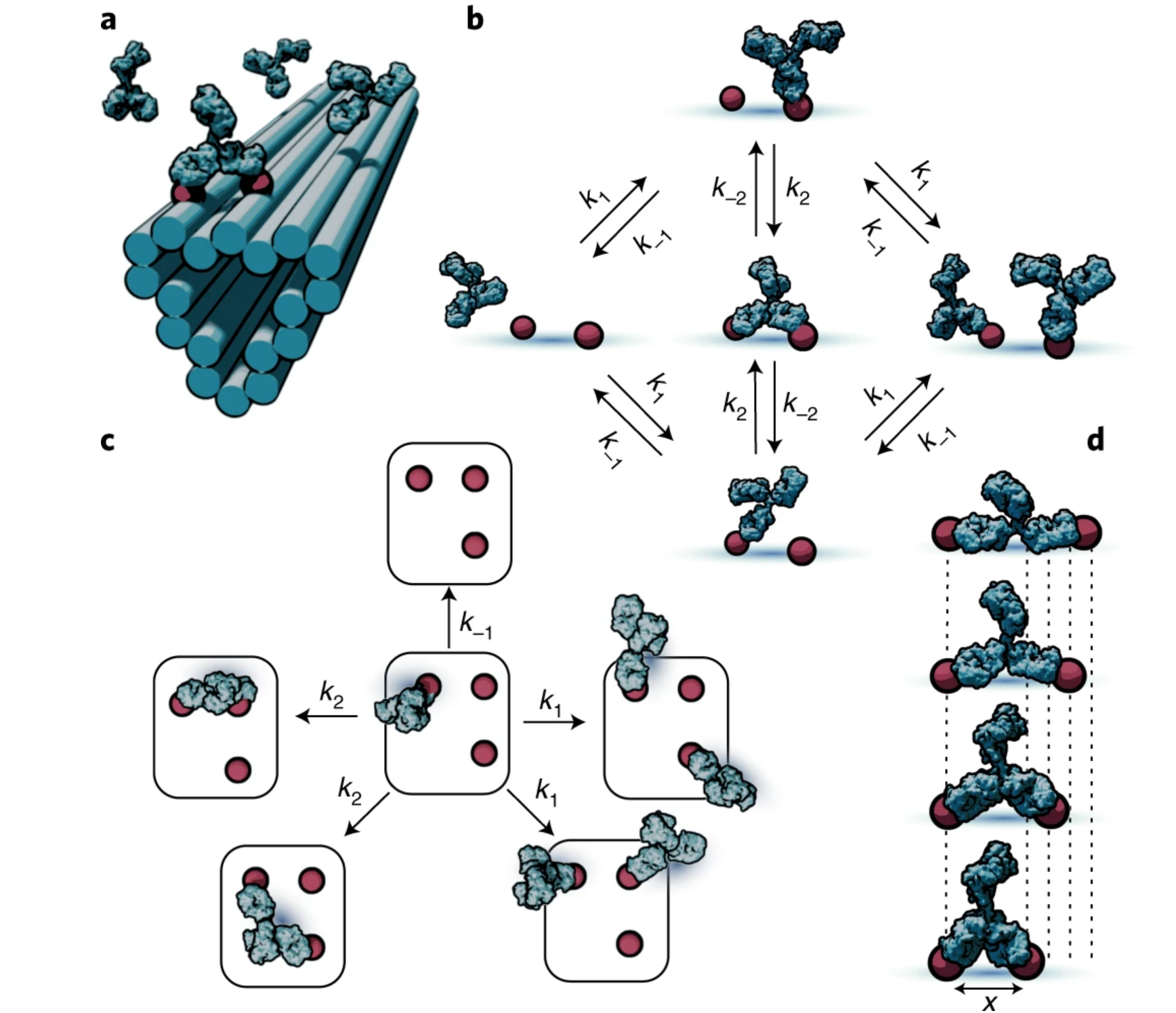
För att komma åt dessa regler använder vi DNA-nanoteknik som ett molekylärt
konstruktionsverktyg. DNA-origami gör det möjligt att placera antigener
med nanometerprecision och att systematiskt variera deras avstånd
och geometri. Genom att kombinera dessa konstruerade mönster med
kvantitativa biofysiska mätningar kan vi direkt mäta
hur antikroppsbindningens styrka, flexibilitet och multivalenta
interaktioner beror på spatial organisation. Denna metod har
visat att antikroppsbindning inte styrs av ett enda optimalt
avstånd, utan snarare speglar ett intervall av spatial tolerans som
beror på antikroppsklass, affinitet och geometri. På så sätt blir
spatial mönstring en kontrollerbar variabel snarare än en
okontrollerad egenskap hos biologin.
Mer övergripande knyter detta arbete an till gruppens centrala tema
molekylär programmering. I stället för att se molekyler som
isolerade aktörer behandlar vi dem som komponenter i ett programmerbart
system, där funktion uppstår genom arrangemang, konnektivitet
och interaktionsregler. Genom att designa molekylära mönster som
kodar specifika spatiala och kinetiska begränsningar skriver vi i praktiken
program som antikroppar och andra biomolekyler utför
genom fysiska interaktioner. Detta perspektiv länkar immunigenkänning
till ett bredare ramverk för molekylär beräkning,
där struktur på nanoskala fungerar både som informationslagring
och som instruktionsuppsättning som styr biologiskt beteende genom
designad molekylär geometri.
Relaterade publikationer och länkar:
- Shaw A, Hoffecker IT, Smyrlaki I, Rosa J, Grevys A, Bratlie D, Sandlie I, Michaelsen TE, Andersen JT, Högberg B. Binding to nanopatterned antigens is dominated by the spatial tolerance of antibodies. Nature nanotechnology. 2019 Feb;14(2):184-90.
nature.com
- Hoffecker IT, Shaw A, Sorokina V, Smyrlaki I, Högberg B. Stochastic modeling of antibody binding predicts programmable migration on antigen patterns. Nature computational science. 2022 Mar;2(3):179-92.
nature.com
- Model shows how antibodies navigate pathogen surfaces like a child at play
eurekalert.org
- DNA origami: A precise measuring tool for optimal antibody effectiveness
sciencedaily.com
DNA-baserade kemiska neurala nätverk
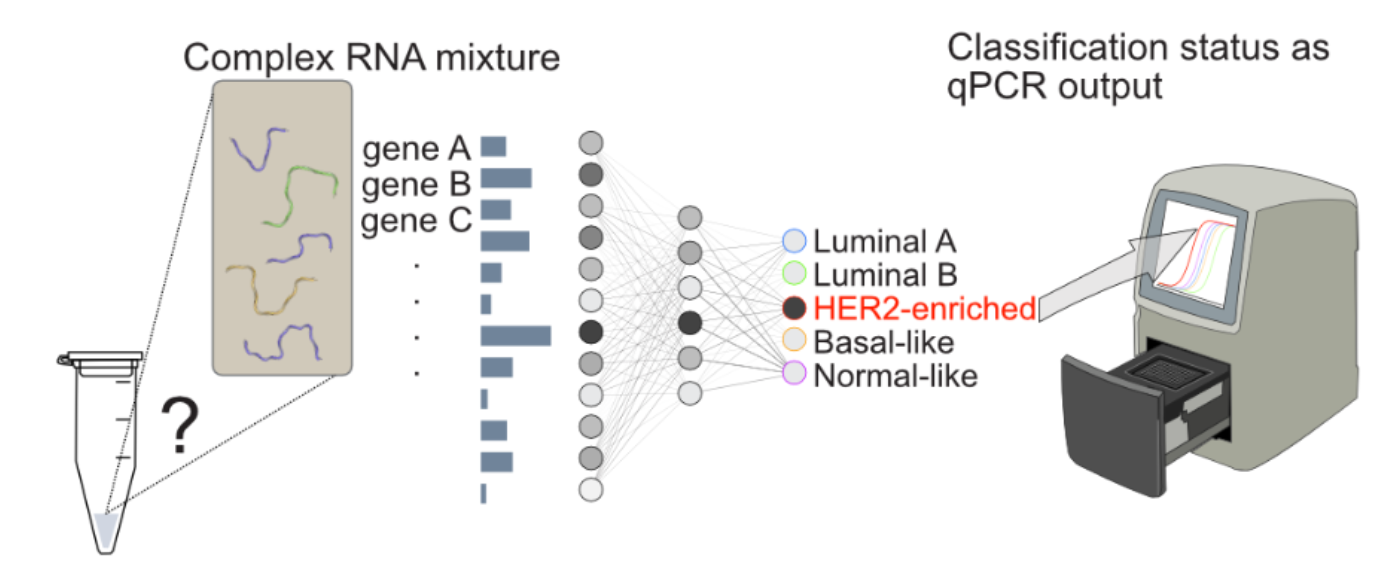
Levande celler bearbetar redan information med hjälp av kemi: molekyler binder,
reagerar och förstärker signaler för att fatta beslut som när de ska dela sig,
differentiera eller svara på stress. DNA-baserad beräkning hämtar inspiration
från denna naturliga logik och frågar om vi medvetet kan programmera
molekyler att utföra informationsbearbetning. I stället för elektroner
som flödar genom kiselkretsar representeras information av
närvaron och de relativa mängderna av DNA-strängar, och beräkningen sker
genom förutsägbara kemiska interaktioner mellan dem. Detta öppnar
möjligheten att utföra komplexa beslutsprocesser direkt i ett provrör
med samma molekylära språk som biologin själv använder.
I vårt arbete undersöker vi hur begrepp från artificiella neurala nätverk
kan översättas till DNA-kemi. I ett neuralt nätverk flödar information
genom viktade kopplingar och icke-linjära aktiveringssteg för att
känna igen mönster snarare än enskilda signaler. Vi återskapar dessa idéer
med hjälp av DNA-sekvensdesign och enzymatiska reaktioner. Styrkan i
interaktionen mellan olika DNA-strängar spelar en roll som liknar
kopplingsvikter, medan polymerasdriven amplifiering introducerar
icke-linjära svar som påminner om neuronal aktivering. Genom att noggrant
designa dessa molekylära interaktioner kan vi bygga kemiska system
som svarar på kombinationer av indata, inte bara på närvaron eller frånvaron
av en enda molekyl.
Detta angreppssätt är särskilt kraftfullt för diagnostik av komplexa sjukdomar
som bröstcancer, där kliniskt relevant information ofta
kodas i mönster av genuttryck snarare än i enskilda biomarkörer.
Idag kräver det vanligtvis sekvensering och
tung beräkningsanalys att känna igen dessa mönster. Vårt mål är att flytta en del av denna
intelligens in i kemin själv. Genom att konstruera DNA-baserade neurala
nätverk som direkt bearbetar blandningar av nukleinsyror kopplade
till sjukdomstillstånd vill vi skapa snabba och kostnadseffektiva diagnostiska
reaktioner som ger en tolkbar molekylär signal. På
längre sikt kan detta bidra till att föra avancerad, mönsterbaserad diagnostik
närmare patienten utan behov av centraliserad sekvenserings-
infrastruktur.
Digital datalagring i DNA

DNA har vuxit fram som ett fascinerande medium för långsiktig informationslagring.
Det är extremt tätt, stabilt över geologiska tidsskalor och produceras och kopieras redan
i enorm skala av biologin själv.
Att översätta dessa fördelar till en praktiskt användbar datalagringsteknik
är dock fortfarande en utmaning.
Dagens metoder möter flaskhalsar kopplade till kostnad och hastighet vid skrivning
samt svårigheten att skala upp systemen.
Många av dessa begränsningar uppstår eftersom DNA-datalagring ofta har behandlats som
en linjär pipeline. Information kodas till sekvenser, syntetiseras, lagras
och sekvenseras och avkodas senare, där varje steg i stor utsträckning optimeras isolerat från de andra.
Detta synsätt har svårt att hantera problem som ojämn sekvensanvändning, förlust av molekyler,
amplifieringsbias och den växande overhead som krävs för felkorrigering och
indexering när datamängderna blir större. Resultatet är ett växande gap mellan
eleganta proof-of-concept-studier och lagringsarkitekturer som skulle kunna fungera
robust i realistiska miljöer.
Vår forskning utforskar ett alternativt perspektiv där DNA-datalagring
behandlas som ett distribuerat och strukturerat system snarare än som en
samling oberoende strängar. I stället för att förlita sig på enskilda sekvenser
som bär isolerade informationsbitar undersöker vi hur
information kan delas, förstärkas och återvinnas genom mönster av
relationer mellan många molekyler. Med inspiration från nätverkade
system vill vi utveckla flera kompletterande strategier som förbättrar
robusthet, skalbarhet och effektivitet i avläsningen samtidigt som de förblir kompatibla
med befintliga molekylära verktyg. Dessa idéer öppnar dörren till DNA-lagrings-
arkitekturer som kan kringgå begränsningarna i klassisk direktlagring via
DNA-syntes.